Last summer I wrote this post which quickly became my most popular one to day. With webpack 2 and 3 it got outdated, so I decided to write a new one.
Before we start #
I'll assume you have a basic knowledge of unix terminal, npm and JavaScript. You did some React, but now you want to level up and learn how setup React projects from scratch.
This is detailed step-by-step guide, as I'll try to explain the whole process. If you just want code to play with, check this repository I created for this tutorial.
Every time I talk about changing a source file, I'll paste complete file's content beneath it.
You can look for ADDED IN THIS STEP comments which point out specific things that changed.
Please note that this tutorial is written on macOS using node 8.5.0, but it should work on Linux and Windows without any major issues. If you find something that is not working, please provide a correction in the comments below.
What are we trying to build? #
Simple development setup for React applications using Webpack and Babel. But my main goal is for people to better understand these tools and how to use them.
Setup that we are going to create is minimal, but it follows the best practices and gives you a solid ground to start from.
Who am I and why should you listen to me? #
Well, I'm a principal developer at Work&Co. I have a lot of experience on production level React projects, for clients like Twitter, Mastercard, Aeromexico, Hampton Creek... Marvin boilerplateWe have big plans for Marvin in the near future. is my creation as well, and what I'm trying to teach you is directly based on my experience on these projects.
Init #
Create a new folder, and package.json file in it, with the following content:
{
"name": "webpack-babel-react-revisited"
}
Of course you can replace "webpack-babel-react-revisited" with your project name.
- package.json
Webpack #
We'll start with installing webpack for module bundling. It will transpile and bundle our JavaScript files, compile SASS or PostCSS, optimize images... and a bunch of other nifty things.
npm install --save-dev webpack
Then we need some modules.
We'll keep our source files in src folder, so we need to create it.
Then create js folder in the src folder you just created, and app.js file in it.
Add a simple console.log('Hello world!'); to app.js;
Now we can run webpack from the terminal for the first time:
./node_modules/webpack/bin/webpack.js ./src/js/app.js --output-filename ./dist/app.bundle.js
If you open generated app.bundle.js you'll see webpack's module handling code at the top,
and at the end you'll find our modest console.log.
Webpack's code does all the work with modules
- connecting them together while keeping them in separate scopes. At this point we are not leveraging that (yet).
This command runs webpack using our app.js as entry and outputs the result to the dist folder.
As it already looks complicated we'll start moving webpack configuration to a file.
Let's create webpack.config.js in our project's root.
We need to add config we just used -
only entry and output paths.Plus paths constant. I like to keep paths in the constant object, as it makes things easier to read.
// We are using node's native package 'path'
// https://nodejs.org/api/path.html
const path = require('path');
// Constant with our paths
const paths = {
DIST: path.resolve(__dirname, 'dist'),
JS: path.resolve(__dirname, 'src/js'),
};
// Webpack configuration
module.exports = {
entry: path.join(paths.JS, 'app.js'),
output: {
path: paths.DIST,
filename: 'app.bundle.js'
},
};
You'll see that we added our app.js as entry and for the output
we selected dist folder and app.bundle.js as the filename.
Now we can run webpack without inline configuration.
By default webpack looks for webpack.config.js and reads config from it.
./node_modules/webpack/bin/webpack.js
This command has the exact same result as the first one. Now let's try to make it even nicer.
Open package.json which at this point should look like this:
{
"name": "webpack-babel-react-revisited",
"devDependencies": {
"webpack": "^3.6.0"
}
}
We'll add script section.
In this sections, let's add build task with only one command - webpack.
{
"name": "webpack-babel-react-revisited",
"devDependencies": {
"webpack": "^3.6.0"
},
"scripts": {
"build": "webpack"
}
}
Now we can run it using:
npm run build
Npm tasks allow us not to type full path to the package binary every time.
It searches for locally installed packages in the project's node_modules folder.
Again, it has the same result like the previous command, but it is cleaner as it uses npm tasks instead of bare terminal commands.
Now we have our simple build process, so we can proceed with development setup.
dist # created by webpack when we run 'npm run build'
node_modules # created by npm
src
js
- app.js
- package-lock.json # created by npm (for node v8 and higher)
- package.json
- webpack.config.js
Webpack dev server #
To be able to open our application in a browser, we'll need a server. Webpack already provides us with a dev server. It will server our files during development (obviosly), but also enable us to use hot module reload (not covered by this post).
Let's install it:
npm install --save-dev webpack-dev-server
Let's update package.json right away to make it easier to run dev server.
{
"name": "webpack-babel-react-revisited",
"devDependencies": {
"webpack": "^3.6.0",
"webpack-dev-server": "^2.9.1"
},
"scripts": {
"dev": "webpack-dev-server",
"build": "webpack"
}
}
We added only one line: "dev": "webpack-dev-server",.
Now if you run
npm run dev
it will fire up our development server, and it is going to be available at http://localhost:8080. Now it will just list our project's files.
So let's create a simple index.html in the src folder
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width">
<title>Webpack Babel React revisited</title>
</head>
<body>
</body>
</html>
and update webpack.config.js to use src as a content base.
// We are using node's native package 'path'
// https://nodejs.org/api/path.html
const path = require('path');
// Constant with our paths
const paths = {
DIST: path.resolve(__dirname, 'dist'),
SRC: path.resolve(__dirname, 'src'), // source folder path -> ADDED IN THIS STEP
JS: path.resolve(__dirname, 'src/js'),
};
// Webpack configuration
module.exports = {
entry: path.join(paths.JS, 'app.js'),
output: {
path: paths.DIST,
filename: 'app.bundle.js',
},
// Dev server configuration -> ADDED IN THIS STEP
// Now it uses our "src" folder as a starting point
devServer: {
contentBase: paths.SRC,
},
};
Every time you change webpack config you need to restart webpack (or webpack dev server).
Restart npm run dev and visit http://localhost:8080, it will just show a blank page.
No signs of our JavaScript.
To automatically inject <script> tags with our bundled application we'll use
html-webpack-plugin.
HTML Webpack Plugin #
This plugin simplifies creation of HTML files to serve your webpack bundles. Let's install it:
npm install --save-dev html-webpack-plugin
Once installed we need to activate it in webpack.config.js.
Require it and add it to the plugins section of
the config:We don't need contentBase: paths.SRC anymore as it will be handled by html plugin.
So we'll remove whole devServer configuration object for now.
// We are using node's native package 'path'
// https://nodejs.org/api/path.html
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin'); // Import our plugin -> ADDED IN THIS STEP
// Constant with our paths
const paths = {
DIST: path.resolve(__dirname, 'dist'),
SRC: path.resolve(__dirname, 'src'),
JS: path.resolve(__dirname, 'src/js'),
};
// Webpack configuration
module.exports = {
entry: path.join(paths.JS, 'app.js'),
output: {
path: paths.DIST,
filename: 'app.bundle.js',
},
// Tell webpack to use html plugin -> ADDED IN THIS STEP
// index.html is used as a template in which it'll inject bundled app.
plugins: [
new HtmlWebpackPlugin({
template: path.join(paths.SRC, 'index.html'),
}),
],
// Dev server configuration -> REMOVED IN THIS STEP
// devServer: {
// contentBase: paths.SRC,
// },
};
When we restart dev task, we'll be able to see Hello world! in the console.
Now we are talking! We can start adding some modern JavaScript.
dist # created by webpack when we run 'npm run build'
node_modules # created by npm
src
js
- app.js
- index.html
- package-lock.json # created by npm (for node v8 and higher)
- package.json
- webpack.config.js
Babel #
To be able to use ES2015 and beyond we'll need to provide a transpiler. Our choice is Babel. Babel takes modern JavaScript and transpiles it - converts it to the old version of JavaScript that can be executed in the browsers that don't support modern JavaScript standards.
We need this for two reasons (and you probably know both already):
- React and JSX heavily rely on modern JavaScript features
- You should use modern JavaScript - it makes things easier and helps you write better code
Let's continue by installing four packages:
- Babel core package
- Babel webpack loader
-
Babel env preset
babel-preset-envis successor ofbabel-preset-es2015and it has couple of big advantages which may be covered in another post. You can read more about using it in this post - Babel React preset
npm install --save-dev babel-core babel-loader babel-preset-env babel-preset-react
Babel also has default config file which is .babelrc, so let's create it in our project's root:
{
"presets": ["env", "react"]
}
This will tell Babel to use two presets we just installed.
Now we need to update webpack.config.js to use Babel loader for .js and .jsx files.
We also added some sugar, so you can import those files without specifying file extension.
// We are using node's native package 'path'
// https://nodejs.org/api/path.html
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
// Constant with our paths
const paths = {
DIST: path.resolve(__dirname, 'dist'),
SRC: path.resolve(__dirname, 'src'),
JS: path.resolve(__dirname, 'src/js'),
};
// Webpack configuration
module.exports = {
entry: path.join(paths.JS, 'app.js'),
output: {
path: paths.DIST,
filename: 'app.bundle.js',
},
// Tell webpack to use html plugin
plugins: [
new HtmlWebpackPlugin({
template: path.join(paths.SRC, 'index.html'),
}),
],
// Loaders configuration -> ADDED IN THIS STEP
// We are telling webpack to use "babel-loader" for .js and .jsx files
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /node_modules/,
use: [
'babel-loader',
],
},
],
},
// Enable importing JS files without specifying their's extenstion -> ADDED IN THIS STEP
//
// So we can write:
// import MyComponent from './my-component';
//
// Instead of:
// import MyComponent from './my-component.jsx';
resolve: {
extensions: ['.js', '.jsx'],
},
};
Restart npm run dev once again. Nothing really changed, but our JavaScript is now transpiled,
and if you used any of the modern JavaScript features, those would be transpiled to ES5 synthax.
Finally let's add React.
dist # created by webpack when we run 'npm run build'
node_modules # created by npm
src
js
- app.js
- index.html
- .babelrc
- package-lock.json # created by npm (for node v8 and higher)
- package.json
- webpack.config.js
React #
This is probably the main reason you are reading this, so I'll assume you are already familiar with React.
Install it (this time as a regular dependency):
npm install --save react react-dom
Let's add div with id app to index.html, in which we'll render our React app.
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width">
<title>Webpack Babel React revisited</title>
</head>
<body>
<div id="app"></div>
</body>
</html>
Finally replace console.log in our app.js with a real React component.
import React, { Component } from 'react';
import { render } from 'react-dom';
export default class Hello extends Component {
render() {
return (
<div>
Hello from react
</div>
);
}
}
render(<Hello />, document.getElementById('app'));
Restart dev server one more time, and voala, we have our React app running!
This is minimal working setup #
At this point, you have bare bones setup for making React apps using Webpack and Babel. You can start exploring on your own, add more stuff and modify it to fit your needs. However in this post I'll cover two more things - CSS and assets loaders.
CSS #
Every web application needs CSS. So let's add a way of getting CSS into ours.
Create src/css folder and a simple style.css in it.
body {
background: #f9fafb;
font-family: Helvetica, Arial, sans-serif;
font-size: 16px;
margin: 0;
padding: 30px;
}
To add this CSS file to the app, we'll use css-loader.
CSS loader needs to write loaded CSS code to either style tag in the head
or external stylesheet file.
If you want to write it to the style tag you should use
style-loader.
But for now, we'll extract it to the external file by using
extract-text-webpack-plugin.
HTML webpack plugin, that we already set, will add css file to index.html for us.
Again, start by installing packages:
Update, April 2018: Please note, if you are using webpack v4.x you'll need to install
extract-text-webpack-plugin@next which is webpack 4 compatible.
npm install --save-dev css-loader extract-text-webpack-plugin
We'll need to do two more things:
- import our CSS in
app.js:
import React, { Component } from 'react';
import { render } from 'react-dom';
import '../css/style.css'; // Import CSS -> ADDED IN THIS STEP
export default class Hello extends Component {
render() {
return (
<div>
Hello from react
</div>
);
}
}
render(<Hello />, document.getElementById('app'));
- and update webpack config to use
css-loaderfor CSS files:
// We are using node's native package 'path'
// https://nodejs.org/api/path.html
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const ExtractTextPlugin = require('extract-text-webpack-plugin'); // -> ADDED IN THIS STEP
// Constant with our paths
const paths = {
DIST: path.resolve(__dirname, 'dist'),
SRC: path.resolve(__dirname, 'src'),
JS: path.resolve(__dirname, 'src/js'),
};
// Webpack configuration
module.exports = {
entry: path.join(paths.JS, 'app.js'),
output: {
path: paths.DIST,
filename: 'app.bundle.js',
},
// Tell webpack to use html plugin
plugins: [
new HtmlWebpackPlugin({
template: path.join(paths.SRC, 'index.html'),
}),
new ExtractTextPlugin('style.bundle.css'), // CSS will be extracted to this bundle file -> ADDED IN THIS STEP
],
// Loaders configuration
// We are telling webpack to use "babel-loader" for .js and .jsx files
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /node_modules/,
use: [
'babel-loader',
],
},
// CSS loader to CSS files -> ADDED IN THIS STEP
// Files will get handled by css loader and then passed to the extract text plugin
// which will write it to the file we defined above
{
test: /\.css$/,
loader: ExtractTextPlugin.extract({
use: 'css-loader',
}),
}
],
},
// Enable importing JS files without specifying their's extenstion
//
// So we can write:
// import MyComponent from './my-component';
//
// Instead of:
// import MyComponent from './my-component.jsx';
resolve: {
extensions: ['.js', '.jsx'],
},
};
This might seem very complicated to get one CSS file to the page, but it is very useful when you have multiple stylesheet files and pre-processing (or post-processing).
Restart npm run dev, and you'll see that five lines of our beautiful CSS are applied on the page.
And if we run npm run build you'll see
style.bundle.cssI use .bundle postfix so you can easier differentiate webpack bundles from the source files.
created in the dist folder,
next to js and html files.
dist # created by webpack when we run 'npm run build'
node_modules # created by npm
src
css
- style.css
js
- app.js
- index.html
- .babelrc
- package-lock.json # created by npm (for node v8 and higher)
- package.json
- webpack.config.js
Assets #
For the end, we'll add file-loader. As it's name suggests it handles files - images, SVGs, fonts, videos or anything else you need.
Let's create /src/assets/ folder and add
Commander Keen imageI still love Commander Keen games.
in it.
{kind=link}
Follow the same flow as with CSS files
- install loader
npm install --save-dev file-loader
- import image in
app.jsand render it
import React, { Component } from 'react';
import { render } from 'react-dom';
import '../css/style.css';
import keenImage from '../assets/keen.png'; // Importing image -> ADDED IN THIS STEP
export default class Hello extends Component {
render() {
return (
<div>
Hello from react
{/* ADDED IN THIS STEP */}
<img src={ keenImage } alt='Commander Keen' />
</div>
);
}
}
render(<Hello />, document.getElementById('app'));
- update webpack config to handle image assets
// We are using node's native package 'path'
// https://nodejs.org/api/path.html
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
// Constant with our paths
const paths = {
DIST: path.resolve(__dirname, 'dist'),
SRC: path.resolve(__dirname, 'src'),
JS: path.resolve(__dirname, 'src/js'),
};
// Webpack configuration
module.exports = {
entry: path.join(paths.JS, 'app.js'),
output: {
path: paths.DIST,
filename: 'app.bundle.js',
},
// Tell webpack to use html plugin
plugins: [
new HtmlWebpackPlugin({
template: path.join(paths.SRC, 'index.html'),
}),
new ExtractTextPlugin('style.bundle.css'), // CSS will be extracted to this bundle file -> ADDED IN THIS STEP
],
// Loaders configuration
// We are telling webpack to use "babel-loader" for .js and .jsx files
module: {
rules: [
{
test: /\.(js|jsx)$/,
exclude: /node_modules/,
use: [
'babel-loader',
],
},
// CSS loader for CSS files
// Files will get handled by css loader and then passed to the extract text plugin
// which will write it to the file we defined above
{
test: /\.css$/,
loader: ExtractTextPlugin.extract({
use: 'css-loader',
}),
},
// File loader for image assets -> ADDED IN THIS STEP
// We'll add only image extensions, but you can things like svgs, fonts and videos
{
test: /\.(png|jpg|gif)$/,
use: [
'file-loader',
],
},
],
},
// Enable importing JS files without specifying their's extenstion
//
// So we can write:
// import MyComponent from './my-component';
//
// Instead of:
// import MyComponent from './my-component.jsx';
resolve: {
extensions: ['.js', '.jsx'],
},
};
Restart npm run dev and refresh the browser to see the image.
npm run build will create image in the dist folder.
dist # created by webpack when we run 'npm run build'
node_modules # created by npm
src
assets
- keen.png
css
- style.css
js
- app.js
- index.html
- .babelrc
- package-lock.json # created by npm (for node v8 and higher)
- package.json
- webpack.config.js
That was quite a ride #
And all that to create a very simple application, that should look something like this:
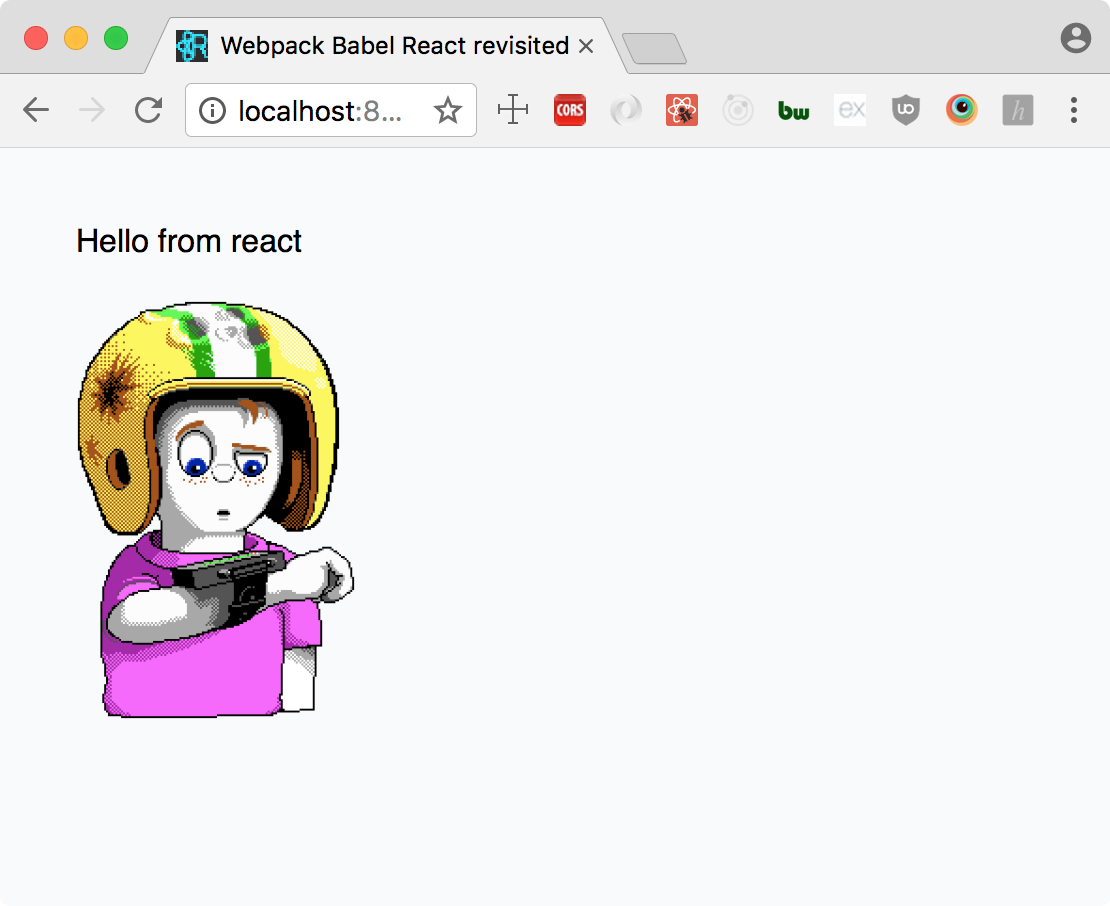
Hopefully, you now understand webpack better and are able to create new apps from scratch.
If you enjoyed this tutorial, please share it, and help me improving it by pointing out things that are not clear enough or could be written better.
Complete code is available in this repository.
But I want more! #
Don't worry, I will cover more in posts to come. But it might take a while, as creating a meaningful tutorial is really time consuming. So please, bear with me.
{kind=link}
This new tutorial series is closely related to Marvin's future. So there will posts about development of Marvin and setting up React applications using React.
React router, redux, hot module reload, thunks, sagas, SASS, PostCSS, universal rendering are some of the themes that I want to write about.
Cheers!
Comments (79)